eix
Tecnologies Lingüístiques
Sobre l’eix de Tecnologies Lingüístiques
Tecnologies al servei de persones, comunitats, llengües i cultures
Volem un futur on totes les cultures i llengües puguin florir digitalment. Per això des de l’eix de tecnologia catalitzem el desenvolupament de recursos lingüístics digitals amb el suport de la comunitat i desenvolupem productes innovadors que amplien l’abast de la informació i enforteixen les xarxes comunicatives de poblacions minoritzades.
Digitalització lingüística
Promovem la presència i el creixement de llengües minoritzades, com el català, l’amazic o l’aranès, a l’era digital. N’enfortim les dades, creem models oberts i desenvolupem tecnologies innovadores.
Intel·ligència artificial col·lectiva
Avancem amb eines d'intel·ligència artificial (IA) per a l'automatització lingüística: traducció automàtica (MT), reconeixement automàtic de la parla (STT), text a veu (TTS) i models de llenguatge extensos (LLMs).
Codi obert
Fomentem el coneixement amb solucions de codi i dades obertes. Podeu explorar els nostres projectes a Github i els nostres conjunts de dades a Hugging Face.
Solucions personalitzades i replicables
Creem solucions a mida, adaptades a les necessitats específiques de cada client, garantint la màxima eficàcia i impacte en els seus projectes.
Serveis
Serveis de processament del llenguatge natural
Elaborem conjunts de dades personalitzats que serveixen de fonament per a models d'aprenentatge automàtic. Desenvolupem i despleguem models a mida per al reconeixement automàtic de la parla (STT o ASR), la traducció automàtica (MT), el text a veu (TTS) i els models de llenguatge extensos (LLMs), satisfent les vostres necessitats lingüístiques específiques.
Solucions integrades d'automatització lingüística
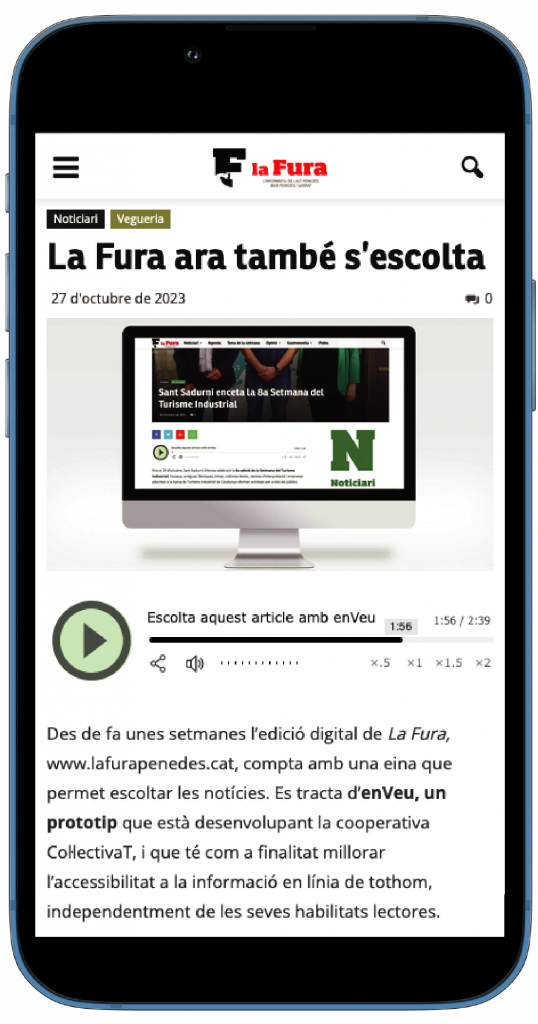
Les nostres interfícies de programació d'aplicacions (API) avançades per a traducció automàtica i de text a veu aporten capacitats multilingües i veu a les vostres plataformes, tant en línia com en dispositius. El nostre producte estrella, enVeu, té la capacitat de donar veu a milers d'articles de notícies, expandint l'accessibilitat i abast de la informació.
Transcripció automàtica
Per a facilitar-vos les tasques de recerca i documentació, oferim serveis de transcripció automàtica per convertir les vostres entrevistes en transcripcions estructurades. Utilitzem models d'última generació per a mantenir l'exactitud i la privacitat dels continguts amb què treballeu. Des de l'eix de serveis lingüístics també duem a terme transcripció manual.
Serveis de capacitació i formació
Amb l'objectiu de fomentar el coneixement i les habilitats entre professionals de la llengua, persones investigadores, ONGs i comunitats lingüístiques, oferim sessions especialitzades sobre processament del llenguatge natural (PLN), intel·ligència artificial (IA), automatització lingüística i altres.
Projectes
Solucions Integrades
enVeu
enVeu és una aplicació que transforma automàticament el text web en àudio, obrint una nova manera de connectar els continguts digitals amb el públic. Aquesta solució innovadora amplia l’accés i fomenta la inclusió, l’accessibilitat i el confort per a totes les persones lectores de mitjans de comunicació.
enVeu és ideal per a mitjans de comunicació, espais de creació de contingut digital i plataformes educatives que busquen connectar de manera més eficaç amb una audiència diversa per raons d’edat, coneixements lingüístics, diversitat funcional, ritmes vitals, etc.
enVeu fa que la informació sigui accessible per a persones amb discapacitat visual o dificultats de lectura. Facilita l’accés universal a la informació mitjançant formats auditius.
El reproductor enVeu es pot integrar fàcilment als llocs web, oferint opcions personalitzables per adaptar-se a la identitat de cada pàgina i millorar així l’experiència de les usuàries.


Digitalització Lingüística
Projecte Araina
El Projecte Araina és una iniciativa col·laborativa que busca preservar i revitalitzar la llengua aranesa, una varietat de l’occità parlada a la Val d’Aran, Catalunya. Mitjançant l’ús de tecnologies lingüístiques avançades, aquest projecte contribueix a assegurar el futur de l’aranès en l’entorn digital.
Hem col·laborat amb el projecte Common Voice per impulsar el recull de dades de veu diverses en aranès. Gran part d’aquestes les hem enregistrat a la Marató de Veus celebrada a Vielha, gràcies a la participació de la comunitat local amb persones de diverses edats, gèneres i parlars.
El projecte és una col·laboració amb la Universitat de Lleida i el Conselh Generau d’Aran. Aquesta aliança ha estat essencial per a la recopilació de dades, el desenvolupament de models lingüístics i la promoció de la llengua aranesa.
El Projecte Araina ha estat pioner en la creació de tecnologies lingüístiques per a l’aranès, obrint la porta a col·laboracions amb altres entitats com Lo Congrès i el projecte Linguatec-IA. Aquestes sinergies permeten ampliar l’abast i l’impacte del projecte en la preservació i la promoció de la llengua aranesa.

Digitalització Lingüística
AWAL
AWAL és un projecte en col·laboració amb el CIEMEN i Casa Amaziga que busca digitalitzar la llengua amaziga, preservant-la i promovent-la en l’espai digital a través del desenvolupament d’eines innovadores que facilitin el seu ús i difusió.
Hem construït el portal awaldigital.org com a plataforma central per a la recopilació de dades lingüístiques. Aquest portal permet a qualsevol persona contribuir amb frases traduïdes i enregistraments de veu, creant així un recurs lingüístic ric i divers per a la comunitat amaziga.
Hem desenvolupat i integrat models de traducció automàtica per a l’amazic, utilitzant les dades recopilades per crear eines de codi obert que millorin l’accés i la utilització de la llengua amazic.
Hem treballat estretament amb la comunitat amazic tant a Catalunya com al Marroc, assegurant que el projecte respongui a les necessitats reals i promogui la llengua de manera efectiva.
Digitalització Lingüística
Judeocastellà: connectant les dues ribes de la Mediterrània
Judeocastellà: connectant les dues ribes de la Mediterrània és un projecte desenvolupat per les organitzacions Col·lectivaT, amb seu a Barcelona, i SKAD, amb seu a Istanbul, i finançat per la Unió Europea. El seu objectiu és contribuir a la supervivència de la llengua ladina i la cultura sefardita a l’espai digital. A través de la implementació de tecnologies de codi obert i la creació de xarxes de comunitats lingüístiques entre les dues ribes del Mediterrani, el projecte busca també promoure i divulgar bones pràctiques de preservació digital per a altres llengües i cultures minoritzades.
Hem generat una aplicació de traducció automàtica del judeocastellà cap a i des de tres idiomes: el turc, el castellà i l’anglès. En crear i integrar una aplicació de síntesi de veu, també hem fet les traduccions audibles, permetent a les persones usuàries practicar la pronunciació. Hem presentat la nostra metodologia en diversos tallers especialitzats en Processament del Llenguatge Natural (NLP) per a llengües en perill d’extinció.
En diversos tallers a Turquia i Catalunya sota el lema ‘Que cap idioma es quedi enrere de l’era digital’, hem compartit les experiències i aprenentatges recollits durant el projecte i els mètodes emprats per a la preservació i promoció del judeocastellà. Per compartir els resultats obtinguts amb la comunitat de parlants de llengües minoritzades, hem organitzat diverses taules rodones a ambdós territoris. També hem elaborat un document de bones pràctiques per a la preservació digital del patrimoni cultural, destinat a parlants, lingüistes i investigadores de llengües en perill d’extinció a l’Estat espanyol, Turquia i altres regions.
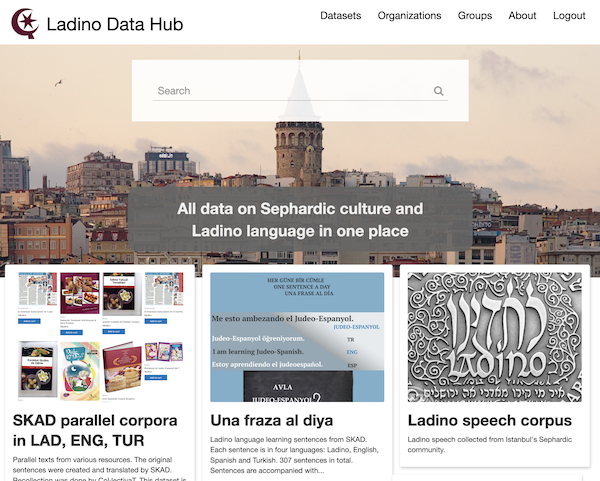
Hem creat l’eina Ladino Data Hub, una compilació de dades del llenguatge en judeocastellà considerades com a patrimoni cultural general. Amb aquesta aplicació, centralitzem les dades disponibles sobre la cultura sefardita i la llengua ladina en un únic punt d’accés obert. Això inclou dades de text paral·lel, un diccionari digitalitzat, un corpus de veu de parlant única i múltiples parlants i un corpus de text extens recopilat durant el projecte.



Eina
Catotron i altres tecnologies per al català
A Col·lectivaT, impulsem la digitalització del català mitjançant tecnologies lingüístiques avançades. El nostre objectiu és crear solucions inclusives i justes que permetin a la llengua catalana prosperar en l’era digital. Des de la creació de grans conjunts de dades de parla multilocutors fins al desenvolupament de models de síntesi de veu i reconeixement automàtic de la parla, la nostra feina contribueix a enfortir la presència del català en l’entorn digital.
En aquesta línia de treball hem creat Catotron, el primer sistema de síntesi de veu en català basat en xarxes neuronals. Aquest sistema converteix el text escrit en veu parlada en català, produint veus amb diverses identitats de parlants, estils i emocions. Catotron és una eina de codi obert que facilita la seva adopció per part de desenvolupadores i investigadores.
Hem creat el primer gran conjunt de dades de la parla multilocutors per al català i l’hem ampliat fins a obtenir un total de 560 hores de dades. Aquest corpus de veu, recollit al nostre repositori Hugging Face, és fonamental per al desenvolupament de models de síntesi de veu i altres aplicacions lingüístiques.
Hem desenvolupat un model de reconeixement automàtic de la parla (ASR) per al català, contribuint a que la informació en aquesta llengua sigui més accessible. Aquest model ha estat publicat en una conferència científica, demostrant la seva eficàcia i precisió.
Testimonis
Referències de les persones i entitats amb qui treballem
L’Alp i el seu equip ens van ajudar a dur a terme tasques de reconeixement de la parla per a preparar el nostre corpus oral del català. Va ser una col·laboració molt útil i eficaç per al nostre projecte de la Universitat de València. Sens dubte, continuarem treballant junts perquè Col·lectivaT ens ofereix el suport tecnològic que necessitem i perquè també som de l’opinió que és molt important treballar amb recursos de codi obert.
Andreu Sentí
Departament de Filologia Catalana de
Universitat de València
El Dr. Alp Öktem de Col·lectivaT ha estat part integrant de l’Escola de Localització des dels seus inicis, impartint cursos de formació excepcionals en traducció automàtica, intel·ligència artificial i processament del llenguatge natural (PLN). La seva àmplia experiència, combinada amb una notable metodologia docent que simplifica conceptes complexos en elements fàcilment digeribles, el converteixen en el professor perfecte per guiar el nostre alumnat a través de les assignatures de PLN.
Gökhan Doğru
Translation Technologies Academy
